Content representation
The DECTE content is provided in several types of representation: audio, orthographic transcription, part-of-speech tagged orthographic transcription, and phonetic transcription. Not all types of representation are available across all the TLS, PVC, and NECTE2 components, however.
Table 1 indicates which types of representation are currently available in each of the three subcorpora:
| Table 1. Levels of representation in the three subcorpora of DECTE |
| Subcorpus |
Audio |
Orthographic
transcription |
Part-of-speech tagged
orthographic transcription |
Phonetic
transcription |
| TLS |
✔ |
✔ |
✔ |
✔ |
| PVC |
✔ |
✔ |
✔ |
✖ |
| NECTE2 |
✔ |
✔ |
✖ |
✖ |
1. Audio
The primary representation of the TLS, PVC, and NECTE2 interviews is audio-recorded speech.
- The TLS recordings are on analog reel-to-reel tape dating from the early 1970s, and on analog tape cassettes taken from the original tapes in 1994-95. Because they are re-recordings, the cassettes are inevitably of lower quality than the originals. The originals have, however, deteriorated quite badly, especially in recent years, and the cassettes in many cases provide information no longer recoverable from the reel-to-reel tapes.
- All the TLS recordings included in DECTE were digitized from the cassette versions in .wav format at 12000 Hz 16-bit mono (192kbps), enhanced by amplitude adjustment, graphic equalisation, clip and hiss elimination, and regularisation of speed.
- All PVC recordings were digitised in .wav format (256kbps, 16kHz, 16-bit mono) direct from the original DAT tapes.
- The NECTE2 audio files are all original digital recordings, made using a variety of recording equipment. The recordings from 2010-2011 were made in .wav format (the vast majority are 705kbps, 44kHz, 16-bit mono). Due to storage capacity considerations at the time of the earlier NECTE2 recordings, the audio files from 2007-2008 and 2008-2009 exist only in .mp3 format (64kbps, 12kHz mono).
2. Orthographic transcription
DECTE includes orthographic transcriptions for all of the interview audio recordings incorporated from the TLS, PVC, and NECTE2 collections.
The transcriptions of the TLS and PVC material were taken from NECTE, which was guided by protocols used in comparable and successful projects such as Poplack (1989), Poplack and Tagliamonte (1991), and Tagliamonte (2004). The NECTE transcription process consisted of four passes through the audio files, where:
- The first established a base text.
- The second and third were correction passes to improve transcription accuracy.
- The fourth established uniformity of transcription practice across the entire corpus.
For NECTE2 the process was two-stage: the initial transcription and a correction pass.
(a) Capitalization and punctuation
Capitalization and punctuation are syntactic markers. To avoid pre-judging discourse structure, NECTE made it a policy not to use them in transcription. DECTE emended this slightly, so that the TLS and PVC files now have capitalization of proper nouns and the first person pronoun.
The NECTE2 files use both capitalization and punctuation, but they do so inconsistently because each was transcribed by a different student and there was variation in the way that different individuals interpreted the NECTE2 transcription protocol guidelines that they were each given. This inconsistency is not optimal, and the DECTE team's aim is to regularize it as soon as possible.
(b) Spelling
As a general principle, DECTE aimed to use Standard English orthography for transcription, where 'Standard English' is taken to mean spellings of words found in the Oxford English Dictionary. This implies that, where British and US conventions differ, British conventions are used, e.g. colour, theatre, traveller, etc.
Because the TLS and PVC are dialect corpora, however, they contain frequent morphological and lexical segments for which no Standard English spelling exists. In such cases:
- Where the segments are phonetic variants of ones for which a Standard English spelling does exist, that spelling is used. This policy was adopted because DECTE provides sound files, so indications of accent or informality are not needed in the orthographic transcription. It was also a principled decision, given the unreliability of semi-phonetic spelling and the views expressed in Cameron (2001), Preston (2000), Macalay (1991).
- Where the segments are genuinely dialectal and occur in either of the dialect dictionaries of Heslop (1892) and/or Wright (1905), then the dictionary spelling is used.
- Failing the above, spellings were invented by DECTE; these are listed in Appendix 2.
DECTE also includes the orthographic transcriptions produced by the TLS project. These are included partly for historical reasons, and partly because they sometimes have readings which were no longer recoverable by the DECTE transcribers on account of deterioration of the audio tapes.
Electronic copies of the orthographic transcription text on the index cards were made, and the copies were proof-read relative to the cards. No changes of any kind, including corrections, were made. Note that TLS only transcribed the interviewees' utterances, ignoring the interviewer entirely.
3. Part-of-speech tagged orthographic transcription
The DECTE orthographic transcriptions of the TLS and the PVC audio — but not the NECTE2 transcriptions — were part-of-speech tagged during the NECTE project (2001-2005) by the University Centre for Computer Corpus Research on Language (UCREL) at the University of Lancaster, UK, using the CLAWS4 tagger. Interpretation of the results is via the listing of the UCREL C8 tagset.
4. Phonetic transcription
DECTE includes partial phonetic transcriptions of the TLS interviews. These require some detailed discussion.
To realize their main research aim, the TLS team had to compare the audio interviews they had collected at the phonetic level of representation. This required the analog speech signal to be discretized into phonetic segment sequences, or, in other words, to be phonetically transcribed.
The standard way of doing this is to select a transcription scheme, that is, a set of symbols each of which represents a single phonetic segment (for example, the International Phonetic Alphabet, or IPA), and then to partition the linguistically-relevant parts of the analog audio stream such that each partition is assigned a phonetic symbol.
The result is a set of symbol strings each of which represents the corresponding interview phonetically. These strings can then be compared and, if also given a digital electronic representation, the comparison can be done computationally.
The TLS project generated phonetic transcriptions of a substantial part of its audio materials, and they are included in DECTE, but to make them usable in the DECTE context they have required extensive restoration.
This section describes (1) the TLS phonetic transcription scheme and (2) the restoration of the TLS electronic phonetic files.
4.1 TLS phonetic transcription and digital encoding schemes
The TLS team made the simple, purely sequential transcription procedure described above the basis for a rather complex hierarchical scheme for representing the phonetics of the corpus. That scheme has to be understood if its phonetic data is to be competently interpreted, and it is consequently explained in detail.
The TLS hierarchical phonetic transcription scheme was developed in order to capture as much of the phonetic variability in the interviews as possible. To see this, consider what happens when data generated by a sequential transcription procedure is analyzed, and, more specifically, the transcribed interviews are compared.
An obvious way to do the comparison is to count, for each interview, the number of times each of the phonetic symbols in the transcription scheme being used occurs; this yields a phonetic frequency profile for each of the interviews, and the resulting profiles can then be compared using a wide variety of methods.
But such profiles fail to take into account a commonplace of variation between and among individual speakers and speaker groups: that different speakers and groups typically distribute the phonetics of their speech differently in different lexical environments.
Frequency profiles of the sort in question here only say how many times each of the various speakers uses phonetic segment X without regard to the possibility that they distribute X differently over their lexical repertoires. The hierarchical TLS transcription scheme was designed to capture such distributional variation.
The scheme is based on a way of specifying the phonemes of any given dialect which, following Wells (1982), has come to be known as 'lexical sets', and is fairly widely used in English dialectology and historical phonology.
As its name indicates, a lexical set is a set of words. More specifically, it is the set of words that contains a specific phoneme, and thus gives an extensional definition of the phoneme. The set {ship, rib, dim, milk, slither, myth, pretty, build, women, busy}, for example, defines the phoneme /i/ in Standard American and Received Pronunciation British English.
The TLS hierarchical transcription scheme has three levels:
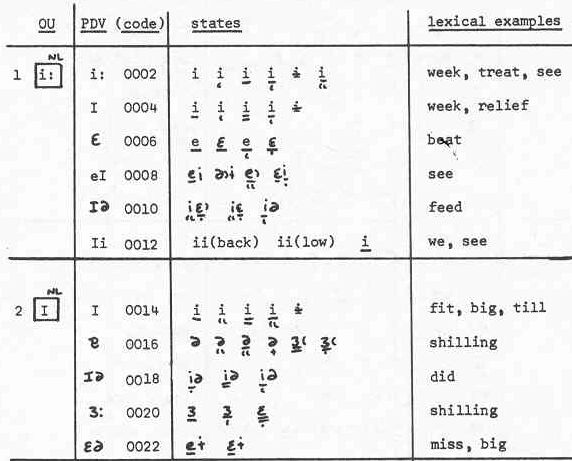
- The top level, designated 'Overall Unit' (OU) level is a set of lexical sets OU = {{ls1}, {ls2}...{lsm}}, such that each {lsi} for 1 < i < m extensionally defines one phoneme in Received Pronunciation (RP) British English, and m is the number of phonemes in RP. The purpose of this level was to provide a standard relative to which the lexical distribution of Tyneside phonetic variation could be characterized.
- The bottom level, designated 'State', is a set of phonetic symbol sets State = {{ps1}, {ps2}...{psm}}. There is a one-to-one correspondence of lexical sets at the OU level and phonetic symbol sets at the State level, such that the symbols in {psi}, for 1 < i < m, denote the phonetic segments that realize the OU {lsi} in the fragment of Tyneside English that the TLS corpus contains.
- The intermediate Putative Disystemic Variable (PDV) level proposes (thus 'putative') groupings of the phonetic symbols in a given State set {psi} based, as far as the existing TLS documentation allows one to judge, on the project team's perceptions of the relatedness of the phonetic segments that the symbols denote. These PDV groups represent the phonetic realizations of their superordinate OUs in a less fine-grained way than the State phonetic symbol sets.
For example (Jones-Sargent 1983: 295):
The OU /i:/ defined by the lexical set from which there are examples in the rightmost column can be realized by the phonetic segment symbols in the States column, and these symbols are grouped by phonetic relatedness in the PDV column.
This transcription scheme captures the required distributional phonetic information by allowing any given State segment to realize more than one OU. In the above figure, note that several of the State symbols for OU /i:/ occur also in the OU /I/. What this means is that, in the TLS transcription scheme, a State phonetic segment symbol represents not a distribution-independent sound, but a sound in relation to the phonemes over which it is distributed.
The implications of this can be seen in the encoding scheme that the TLS developed for its transcription scheme so that its phonetic data could be computationally analyzed. Each State symbol is encoded as a five-digit integer. The first four digits of any given State symbol designate the PDV to which the symbol belongs, and the fifth digit indexes the specific State within that PDV.
Thus, for the OU /i:/ there are 6 PDVs, each of which is assigned a unique four-digit code; the specifics of which numbers are used are irrelevant, and could have been anything else. For a given PDV within the /i:/ OU, say 'I' (0004), the first of the state symbols in left-to-right order is encoded as 00041, the second as 00042, and so on.
Now, note that the State symbols 00023 and 00141 are identical, that is, they denote the same sound. Crucially, however, they have different codes because they realize different phonemes relative to OU, or, in other words, the different codes represent the phonemic distribution of the single sound that both the codes denote.
The complete TLS phonetic transcription scheme is available in Appendix 1.
4.2 Restoration of the TLS phonetic transcriptions
The phonetic transcriptions of the TLS interviews survive in two forms: as a collection of index cards, and as electronic files. Each electronic file is a sequence of the 5-digit codes just described; a random excerpt from one of these files looks like this (&&&& sequences are end-of-line markers):
02441 02301 02621 02363 02741 02881 02301 01123 00906 02081-&&&&
02322 02741 02201 02383 02801 02421 02501 01443 01284 00421 02021 00342 02642 02164 02721 02741 04321-&&&&
02621 02825 02301 02721 02341 02642 02541 00503 00161 00246 12601 01284 02781 02561 02363 02561 02881 07641 02941-&&&& |
The electronic files initially appeared to be a labour and time saving alternative to keying-in the numerical codes from the index cards, but a peculiarity that stems from the original electronic data entry by the TLS meant that they had to be extensively edited. The problem arose from the way in which the 5-digit codes were laid out on the index cards:
For reasons that are no longer clear, all the consonant codes were written on one line, and all the vowel codes on the line or lines below. When the TLS team gave these index cards to the University of Newcastle data entry service, the typists entered the codes line by line, with the result that, in any given electronic line, all the consonant codes come first, followed by the vowel codes. This problem pervades the TLS electronic phonetic transcription files.
Simply to keep this ordering would have made the phonetic representation difficult to relate to the other levels of representation (the orthographic transcriptions and the audio). During the NECTE project, the TLS files were therefore edited with reference to the index cards so as to restore the correct code sequencing, and the result was proofread.
The only exception to this restoration are the files for the Newcastle speakers. Because neither the audio recordings nor the index card sets for these speakers survive, restoration of the correct sequencing would have been a hugely time-consuming task, and one that could not be undertaken within
the limited time that was available to the NECTE project.
Even in their unordered state, however, these files are still usable for certain types of phonetic analysis such as ones that involve segment frequency counts, and they were therefore included in NECTE (and are now included in DECTE) in their present state for that reason.
Moreover, the formatting of numerical codes in these files differs from that in the other TLS-based files, where the codes are in a continuous sequence. For the Newcastle files, the original TLS formatting has been retained: the numerical codes are arranged in a sequence of code-strings each of which is terminated by a line-break, where a code-string in the sequence corresponds to a single informant utterance.
The motivation was to facilitate re-ordering of the codes if this is ever undertaken in future — if, for example, the audio files or the index card sets for the Newcastle group should ever come to light.
It should, finally, be noted that the Gateshead TLS transcriptions were done exclusively by a single member of the project, Vince McNeany, who was both a trained phonetician and a native speaker of the Tyneside dialect of which the TLS corpus is a sample. This is important for analysis of the phonetic level because it minimizes the subjectivity and variation that inevitably compromises phonetic transcriptions. Who did the TLS Newcastle transcriptions is unknown, however.
|