| THE NEWCASTLE ELECTRONIC CORPUS OF TYNESIDE ENGLISH |
|
| THE NEWCASTLE ELECTRONIC CORPUS OF TYNESIDE ENGLISH |
|
|
|
Documentation: TLS and PVC base corpora 1. The Tyneside Linguistic Survey (TLS) corpus To judge from the project papers and public output of the Tyneside Linguistic Survey, its main aim was to determine whether systematic phonetic variation among Tyneside speakers could be significantly correlated with their social characteristics. To this end a methodology was developed that was radical at the time and remains so today: in contrast to the then-universal and still-dominant theory driven approach, where social and linguistic factors are selected by the analyst on the basis of some combination of an independently-specified theoretical framework, existing case studies, and personal experience of the domain of enquiry, TLS proposed a fundamentally empirical approach in which salient factors are extracted from the data itself and then serve as the basis for model construction. The aims and methodology of the TLS project are described in Strang (1968), Pellowe et al. (1972), Pellowe & Jones (1978) and Jones-Sargent (1983). To realize this research aim, TLS created a corpus of spoken Tyneside English. It consisted of the following components:
These components are fully described in Jones-Sargent (1983). The electronic files were created in order to allow the corpus to be computationally analyzed, whereby implementing the TLS empirical methodology. The analysis and its results were described in Jones-Sargent (1983) and Jones (1985). Thereafter, development and analysis of the TLS corpus languished. The audio tapes and index card sets were stored in the Department of English Language (now part of the School of English Literature, Language, and Linguistics) at the University of Newcastle upon Tyne. In addition, John Local, one of the TLS researchers, deposited 6 audio recordings with the British Library Sound Archive, and the electronic files were lodged with the Oxford Text Archive. In 1994-5 Joan Beal of the School of English Literary and Linguistic Studies at Newcastle University secured funding from the Catherine Cookson Foundation to (i) salvage the by then rapidly deteriorating audio tapes by re-recording them onto cassette tape, (ii) catalogue them, and (iii) archive the tapes, the index card sets, and documentation associated with the TLS project in a new Catherine Cookson Archive of Northumbrian Dialect at the University of Newcastle. Since 2001, the NECTE project has based the TLS part of its work on the material in the Catherine Cookson Archive and on the electronic holding at the Oxford Text Archive. It quickly became clear that only a fragment of the original TLS corpus has survived. What is not clear is how much has been lost. The problem is that the information in TLS project documentation and public output do not allow one to decide with any certainty how large the corpus originally was. How many interviews were recorded? Pellowe et al. (1972, 24) claims 150 whereas Jones-Sargent (1983, 2) says there were 200. Were all the interviews orthographically and phonetically transcribed, and, if not, how many were? Jones-Sargent (1983) used 52 (digitally-encoded) phonetic transcriptions in her analysis, but the TLS material includes 7 electronic files that she did not use --there were clearly more than 52 phonetic transcriptions, but how many more? All one can do in this situation is catalogue what currently exists. NECTE has been able to identify 114 interviews, but not all corpus components exist for each. Specifically, there exist:
The distribution of these materials across interviews is shown in the following table. The table is divided into two main but unequal parts: the first and by far the larger lists 107 interviews done in Gateshead, and the second lists 7 done in Newcastle. Within each part there is no natural order to the interviews, so where applicable they are arranged in descending order of how many components they have: the interviews having all four components are at the top of the table, those with only three components below those, and so on:
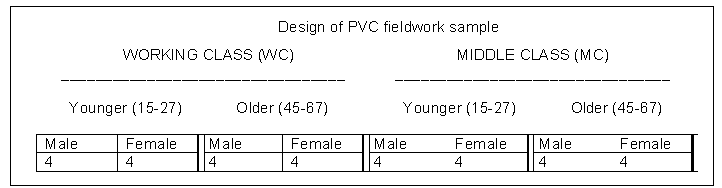
When the interviews are arranged in this way it is easily seen that, out of 114 interviews, only 37 are complete in the sense that an intact audio recording, an index card set, and electronic phonetic transcription and social data files exist; all the others are fragmentary to greater or lesser degrees. 2. The Phonological Variation and Change in Contemporary Spoken English (PVC) corpus PVC's primary research aim, as the title of the project suggests, was to examine patterns of phonological variation and change in contemporary spoken British English. The methodology of this study and some results from it can be found in Milroy et al. (1997), Docherty & Foulkes (1999) and Watt & Milroy (1999). The primary PVC materials comprise 18 digital audio-taped interviews, each of up to 60 minutes' duration. Self-selected dyads of friends or relatives conversed freely about a wide range of topics with minimal interference from the fieldworker. By contrast to the detailed phonetic transcriptions provided by the TLS, the PVC team restricted their transcription to those specific lexical items in phonetic context that they were interested in analysing from auditory and/or acoustic perspectives. No systematic orthographic transcription of the material, such as that produced by the TLS, was ever attempted. As Table 1 below (adapted from Watt & Milroy 1999: 27) demonstrates, the PVC project did, however, record some social data, though it was not as detailed as that of the TLS’ team, since they restricted their categorization of subjects to age, gender and “broadly defined socio-economic class” (Watt & Milroy 1999: 27).
In 1998, Karen Corrigan of the School of English Literary and Linguistic Studies at Newcastle University used the TLS and PVC materials for a real-time sociolinguistic study. The data controllers of the PVC project were approached for permission to use their recordings, and they donated the 18 audio tapes to the Catherine Cookson Archive for this purpose. The first orthographic transcriptions of the PVC corpus were made during this study. |